

Using LLMs to Build A Recommendation Engine
GraphRAG for constraint-aware, explainable recommendations

This publication is by members of the Algorythm Community. A network of 20k+ black software engineers sharing technical insights across all fields of software development. Join us on LinkedIn, Facebook and Subscribe for more insights.
Recommendation engines are incredibly powerful tools that drive the core experiences of social networks, e-commerce, and media platforms. Today, we can create complex recommendation systems much more easily using modern technology, without needing to be machine learning experts.
At a high level, traditional Retrieval-Augmented Generation (RAG) retrieves information based on text similarity, but it struggles with complex, multi-layered constraints. GraphRAG solves this by retrieving structured networks of relationships, giving the LLM precise, deterministic facts to reason over.
To illustrate this, let’s look at real estate as a prime example where recommendations are notoriously challenging and a graph model helps immensely. I’ve had this crazy idea: what if we could utilize GraphRAG and relationships for better recommendations….
Not just “homes similar to what you clicked,” but recommendations that actually understand the web of constraints behind real decisions:
“Like this neighborhood, but quieter.”
“Within 25 minutes of work and close to my partner’s job.”
“Rental-friendly HOA only.”
“Good schools, but still walkable to coffee + gym.”
“Don’t show me places with sketchy parking or bad street noise.”
This moves beyond simple similarity, combining relational structure, strict constraints, and transparent explanations. And that’s exactly where GraphRAG starts to look… weirdly reasonable.
This post is a deep dive into:
What GraphRAG means for recommendation engines,
Why it’s powerful for recommendations involving complex relationships,
What a sane architecture looks like, and
When this is a terrible idea and you should not build it.
The problem with traditional recommendation systems?
Most recommendation systems work well when the goal is straightforward:
“People who viewed X also viewed Y” (collaborative filtering)
“This listing is similar to your tastes” (content-based / embeddings)
“Rank what you’re most likely to click” (learning-to-rank)
But recommendations get messy when you have to weigh dozens of subjective, competing factors. For example in real estate, a user isn’t just selecting a product. They’re making a life impacting decision:
commute time
school district
safety + noise
lifestyle (walkability, parks, gym, groceries)
deal-breakers (HOA rules, pets, rental bans)
social constraints (close to family, near friends)
financial constraints (budget, taxes, insurance)
investment constraints (cap rate, STR legality)
If your system only knows “similar listing text,” it will repeatedly violate user intent in subtle ways. And subtle violations kill trust fast.
So what is GraphRAG in recommendation terms?
GraphRAG = Graph retrieval + LLM reasoning
Instead of retrieving “similar items,” we retrieve a relevant subgraph of facts and relationships that explain why something is a good match.
A simple mental model:
Traditional retrieval: “Give me listings similar to what this user liked.”
GraphRAG retrieval: “Give me listings similar to what this user liked, and also pull the network of constraints and relationships that make those listings relevant.”
Then the LLM uses that retrieved context to:
apply nuanced preferences (“quiet street is more important than granite countertops”),
reason over multi-hop relationships (“this neighborhood is similar to yours because…”),
generate explanations grounded in facts,
ask clarifying questions when constraints conflict.
GraphRAG is not “LLM decides everything.” It’s “retrieve structured context deterministically, then let the LLM reason on top.”
Why real estate here (and where else it applies)?
GraphRAG shines when recommendations require multi-hop reasoning and constraint satisfaction. Real estate is full of that, but this approach easily applies to other datasets that can be modeled as a graph, such as:
Expert matching: weighing required skills, company culture, salary expectations, and remote flexibility.
Travel itineraries: balancing travel dates, group size, interests, and proximity to lodging/transit.
Example of a recommendation that is NOT just similarity: User says: “Show me 3-bed homes similar to what I saved, but I need rental-friendly HOA rules, and my commute must be under 30 minutes.”
A pure embedding search might nail “similar style” but miss HOA rental restrictions, commute constraints, and neighborhood nuances. A graph, though? This is literally graph-shaped.
What does the graph look like?
Let’s model a real estate recommendation graph with a few core node types:
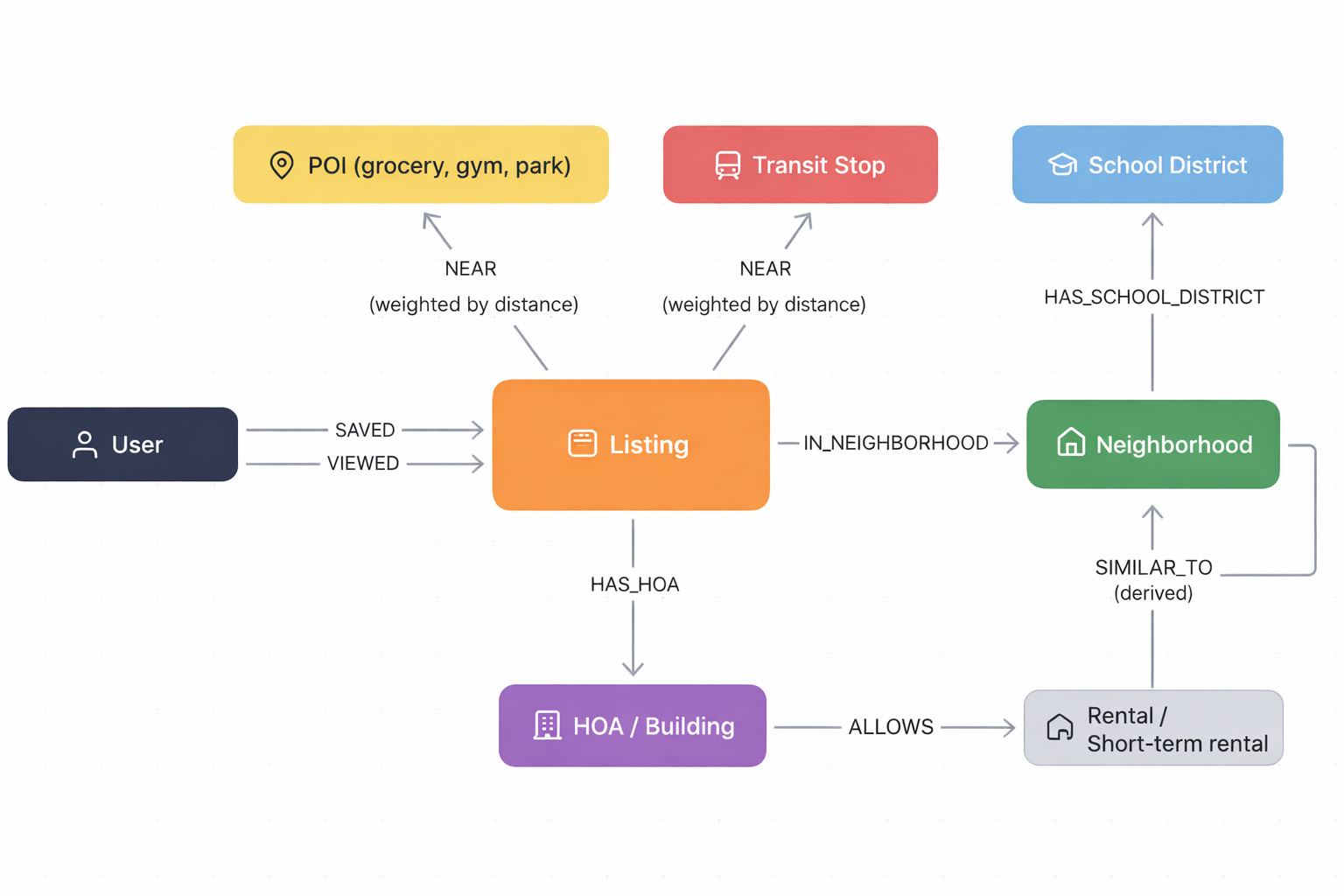
This graph encodes the real question: “What is this user actually optimizing for, and what rules must never be violated?”
What does the workflow look like?
If you’re building this seriously, you typically do it in two stages. To set up your architecture, you need to rely on specific technology choices, balancing trade-offs between speed, cost, and reasoning power.
Architecture & Technology Stack
To build a solid GraphRAG framework, you need to select tools for both generation and reasoning:
Embedding Model
Use a smaller, fine-tuned embedding model (e.g. text-embedding-3-small).
These models are fast, scalable, and highly cost-effective for generating candidate vectors during the initial retrieval phase.
Vector Database
Store and query these embeddings in a robust vector database (e.g. Pinecone).
You need ultra-low latency vector retrieval to execute the first pass of similarity matching efficiently.
Graph Database & Framework
Utilize a graph database (like Neo4j) paired with a framework (like LlamaIndex or Microsoft’s GraphRAG).
This is essential for efficiently mapping and querying the multi-hop relationships required to pull bounded subgraphs without dumping the entire graph into a prompt.
Reasoning LLM
For the final retrieval and ranking, deploy a powerful LLM (like GPT-5 or Claude 4.5 Sonnet).
The second stage requires heavy cognitive lifting to evaluate complex constraints, detect conflicts, and generate grounded explanations. While these models have higher latency and cost tradeoffs, their reasoning capabilities are mandatory for accurate GraphRAG. You can configure the reasoning effort / thinking budget to achieve desired latency.
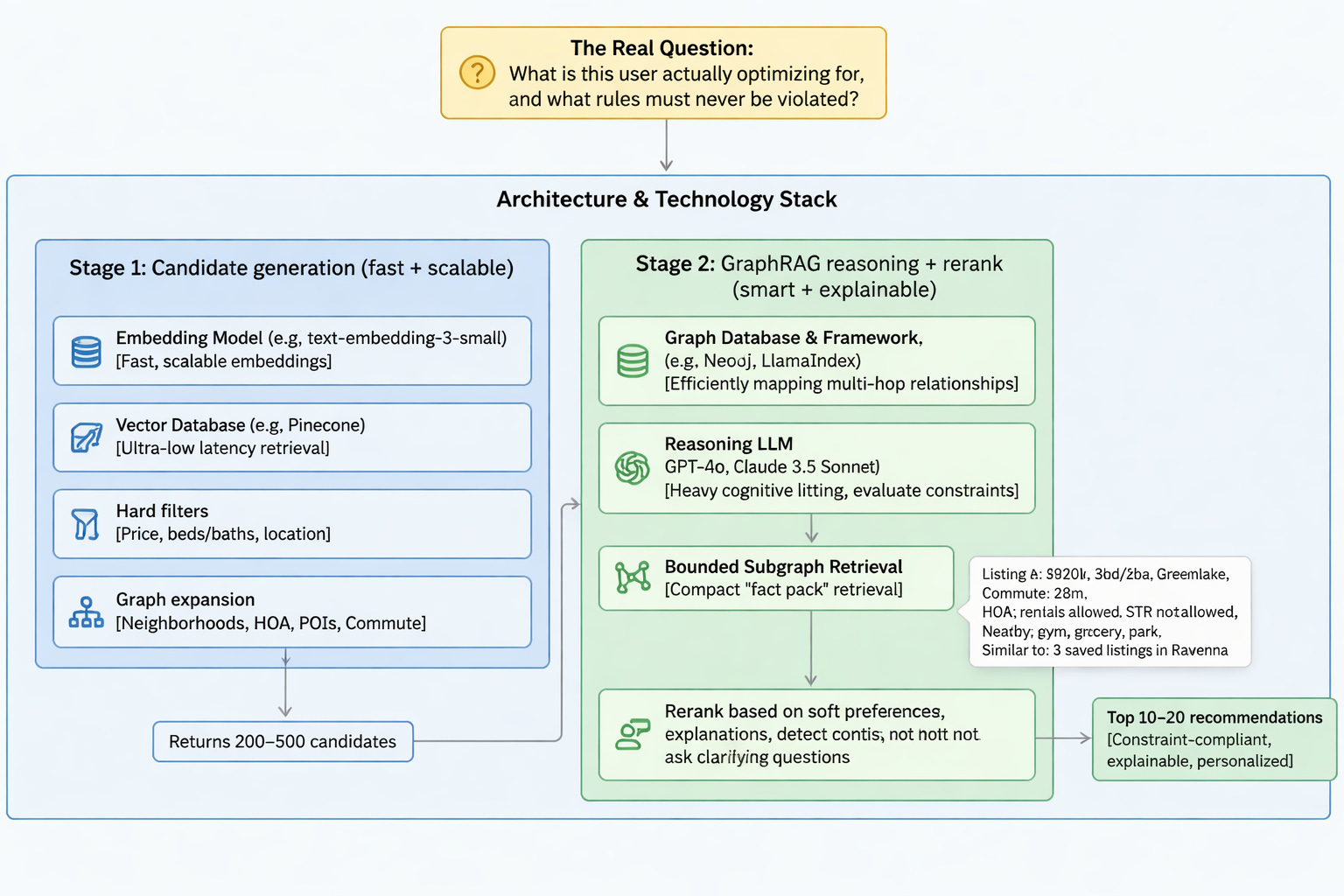
Stage 1: Candidate generation (fast + scalable)
Use a hybrid approach to rapidly narrow down the universe of options:
Hard filters: price, beds/baths, location bounds.
Vector retrieval: utilizing your fine-tuned embedding model and vector DB for listing “vibe/style similarity”.
Graph expansion: neighborhoods the user tends to like, HOA constraints, POIs, commute feasibility.
This stage returns maybe 200–500 candidates.
Stage 2: GraphRAG reasoning + rerank (smart + explainable)
For each candidate (or the top 50), retrieve a bounded subgraph: neighborhood stats, HOA rules, commute time estimate, nearby POIs, similarity link to prior saved listings/neighborhoods.
Now your powerful LLM can do something useful:
rerank based on soft preferences
produce explanations
detect conflicts (e.g., “you want STR but this HOA bans STR”)
ask clarifying questions when needed
You end with top 10–20 recommendations that are constraint-compliant, explainable, and personalized beyond text similarity.
What “bounded subgraph retrieval” looks like?
This is the part people mess up. You do not dump your whole graph into the prompt. You retrieve a compact “fact pack,” like:
Listing A
$820k, 3bd/2ba, 1,750 sqft
Neighborhood: Greenlake
Commute: 28 minutes (typical traffic)
HOA: rentals allowed, STR not allowed
Nearby: gym (0.4 mi), grocery (0.3 mi), park (0.2 mi)
Similar to: 3 saved listings in Ravenna (neighborhood similarity edge)
That’s the “RAG context,” except it’s graph-derived. Now the LLM isn’t guessing; it’s reasoning over facts.
Why GraphRAG can produce better recommendations?
GraphRAG improves recommendations in a few specific ways:
It handles multi-hop constraints: “Close to my sister” → sister’s location → commute edges → neighborhood candidates.
It makes preferences explicit: If a user repeatedly saves homes in quiet neighborhoods, that preference becomes a graph signal — not a vague embedding.
It supports cold-start: New listing? New user? Graph connections still provide signal: neighborhood, HOA, POIs, school district, comps.
It enables real explanations: You can finally answer “Why did you recommend this?” …and not with fluffy nonsense.
When is GraphRAG a terrible idea?
GraphRAG is not the default architecture for recommendations. Avoid it when:
Similarity already solves your problem: If embeddings + LTR gets you 90% of the value, GraphRAG might be expensive “coolness”.
Your graph relationships are weak or noisy: If your edges are mostly heuristics and guesses, you’ll add complexity without real lift.
You need ultra-low latency at massive scale: Graph queries + LLM inference = not cheap, not fast.
Your entity resolution is messy: Graphs break when the same HOA appears under multiple names, addresses aren’t normalized, or entities aren’t deduped cleanly.
You can’t measure lift: GraphRAG feels smart, but you still need constraint satisfaction rates, save rates, lead conversion, and “good match” feedback. If you can’t evaluate, then what are we doing?
A realistic MVP
MVP graph scope - Keep it tight: User ↔ Listing ↔ Neighborhood ↔ HOA ↔ POI
MVP capabilities: hard filters | embedding similarity | HOA rule filtering | neighborhood context + explanation | commute estimation
Use GraphRAG only where it matters: Don’t run GraphRAG on infinite scroll. Run it on high-intent flows like search results refinement, “recommended for you” after saves, or investment mode toggles.
Conclusion
GraphRAG for recommendation engines sounds crazy until you realize that some recommendation problems aren’t primarily similarity problems. They’re relationship + constraint + trust problems.
So if your users care about constraints that must never be violated, multi-hop relationships, grounded explanations, and personalization beyond text similarity… GraphRAG is a serious tool — when used with discipline. Ultimately, this approach extends far beyond real estate; it is a vital framework for unlocking value in any dataset with complex relationships that can be modeled as a graph.
About The Author

Bryan Ofuokwu is an Applied AI Engineer at Salesforce building production AI systems at scale. He explores LLMs, RAG, ML pipelines, and the intersection of software engineering and machine learning.
 | A guest post by
|