

How ChatGPT Understands What You Mean
Attention: The simple idea that kicked off the LLM era

This publication is by members of the Algorythm Community. A network of 20k+ black software engineers sharing technical insights across all fields of software development. Join us on LinkedIn, Facebook and Subscribe for more insights.
Models like Gemini, ChatGPT, and Claude are all built on the same core idea: The Attention Mechanism. This idea enables models to reason over long chats and understand entire codebases. Without this algorithm, we would have likely never entered the large language model (LLM) era.
To better understand the algorithm, we first need to investigate what previous problem it was designed to solve. This requires turning a few pages back and revisiting an older generation of models called recurrent neural networks (RNNs).
RNNs
Recurrent neural networks (which are now archaic on the machine learning timeline) are networks trained on sequential data, like language, where the current element depends on previous elements in the sequence. They allow us to operate over sequences of data. This means that models develop context dynamically as they’re exposed to more sequence positions. Why does the context matter, you ask? Let’s look at an example.
I wrote it in python and ran the script
Without additional context, it’s unclear whether ‘python’ refers to the programming language or the snake. The intended meaning can only be understood by looking at surrounding words.
To explain this more formally (skip this paragraph if you’re allergic to equations), the context (h) is continuously updated as the model sees more tokens (x). At any timestep (t), an RNN has access to the current token (xt) and a context that summarizes all previous tokens (ht-1). This brings us to the core equation for updating a context at any timestep (ht):
where Wx and Wh are learned weight matrices, and b is a bias vector
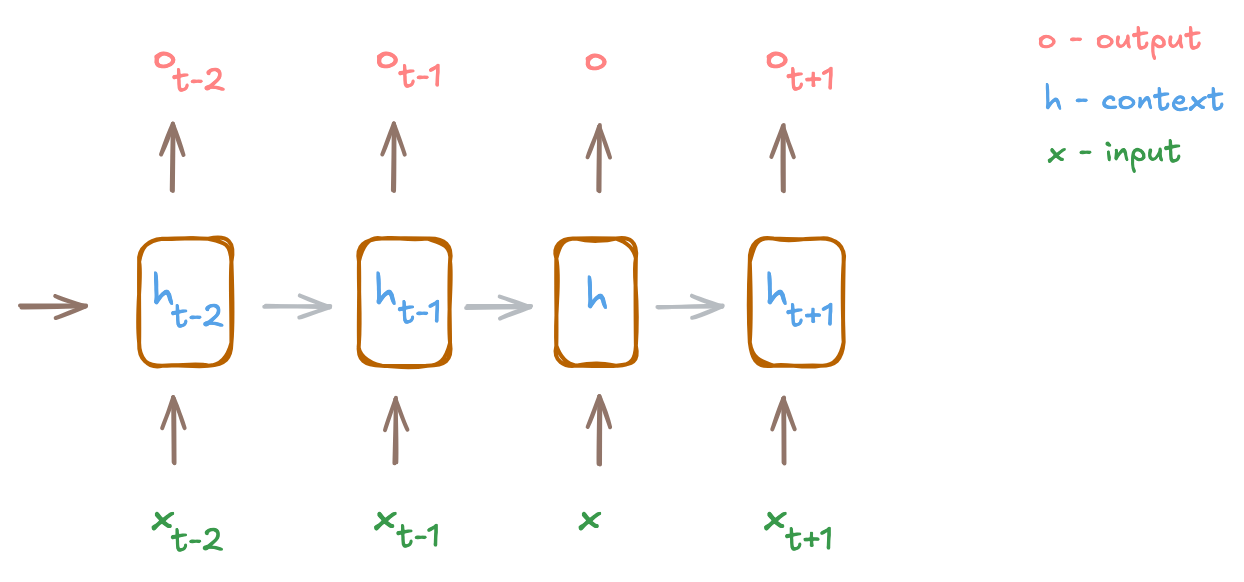
One visible problem here is the packing of all past information into a single vector (ht). As the sequence grows longer, the model is forced to forget some of this information to make room for new information. Can we somehow keep updating the context without sacrificing earlier information? Yes! And that’s where attention comes in.
Attention
Attention allows a model to focus directly on previous tokens and selectively pull important information instead of compressing all past information into a single fixed-size vector. It lets each token decide which other token it needs to focus on and how much information to pull in. How? By projecting the same token representation into three distinct subspaces: query, key and value vectors.
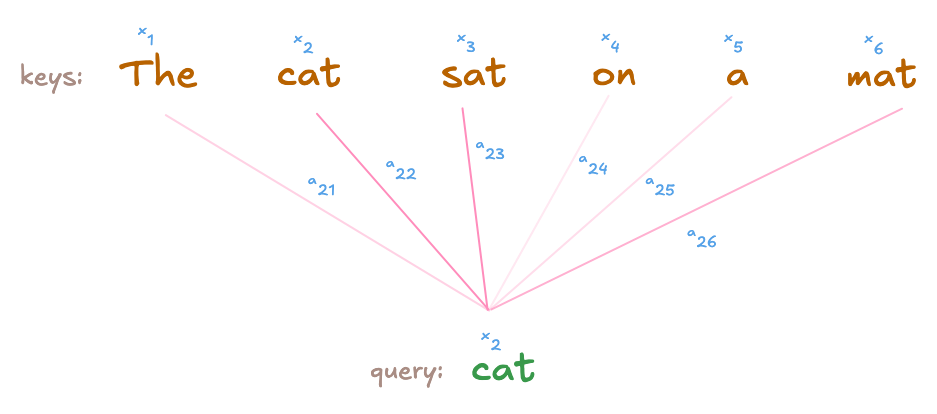
The query and key vectors dictate how much information is transferred between any two tokens. The query vector asks ‘which token is relevant to me?’ while the key vector represents what each token has to offer. By taking the dot product between these two vectors, we can measure their compatibility score. Here is an example.
The cat sat on a mat
The query for ‘sat’ represents the kind of information the token is looking for. It computes a compatibility score with every other token in the sentence by taking the dot product between its query vector and other token’s key vector. Remember, each token has three corresponding vectors: key, query, and value. A high score between the query vector of ‘sat’ and the key vector of ‘cat’ indicates that ‘sat’ should rely heavily on the token ‘cat’ for its downstream tasks (whether next word prediction or machine translation).
Note: Queries as questions and keys as information holders are purely pedagogical metaphors. These are just vectors learned to increase the predictive power of the model.
The above score represents the relevance of the key to the query and determines how much information from the corresponding token’s value vector is incorporated into the querying token’s final representation. Each token’s representation is the weighted sum of all value vectors. For a given token i, the output representation is
where aij is the attention score between tokens i and j and vj is the value vector for token j
But can’t we just have a value vector? If we did, each token’s context would be all previous tokens regardless of how relevant these tokens are to the current token. In other words, every token would contribute equally, forcing the model to treat all past information as equally important. As the sequence grows longer, important information that appeared earlier in the sequence becomes diluted. Attention scores prevent this by ensuring connection is determined by relevance and not distance from the current token.
Hope you now understand why we need three separate vectors derived from the same representation for the attention mechanism to work.
Self-attention vs multi-head attention
So far, we’ve described self-attention, where each token computes a single attention score with each token it’s looking at. In multi-head attention, the model computes multiple attention heads in parallel. Each head has its own query, key, and value projections. This is equivalent to the current token looking at the same other token from different perspectives, inquiring different information (like semantics or syntax) with each head. The output of all heads is then concatenated to form the final representation.
To explain this better, imagine you’re trying to hire a candidate for a position. You’ll likely evaluate them from multiple angles before you make a decision. This can include technical proficiency, teamwork, past experience, and so on. There’s no single metric that can fully capture a candidate’s fit. This is similar to a token considering multiple ‘criteria’ before deciding how much influence other tokens should have over its representation.
Parallelization advantage
The attention mechanism has another advantage, which is particularly attractive for companies building large models (and NVIDIA): parallelization. Sequential data requires sequential processing. But models using attention can compute attention scores between tokens independently of each other. No token depends on the output of another token in the sequence, making the computation highly parallelizable.
Research questions
In this post, we’ve discussed the attention mechanism in depth through formal mathematical definitions and analogies. This might lead you to think that the attention’s role in a model is thoroughly understood. However, understanding how a mechanism computes does not explain why it behaves that way. Despite our current understanding, there are still open questions in the research community as to how exactly each token allocates attention scores to other tokens. In addition, strong attention scores don’t correspond to higher importance or causality. This highlights that much remains to be investigated about this mechanism and its role in creating highly performant and efficient architectures.
About the Author

Ayda Sultan is a machine learning researcher focused on interpreting the internals of large models. Her work centers around understanding how neural networks work internally. She’s an advocate of careful deployment of AI systems and believes AI models can be fully understood and surgically controlled.
 | A guest post by
|