

Building a Distributed Database From Scratch With Rust
A practical deep dive into modern storage engines

This publication is by members of the Algorythm Community. A network of 20k+ black software engineers sharing technical insights across all fields of software development. Join us on LinkedIn, Facebook and Subscribe for more insights.
Many engineers use databases every day. Few ever look inside one. I wanted to change that for myself, so I built youdaheDB a distributed key-value database engine written from scratch in Rust, using only the standard library. No external crates. No frameworks. Just raw bytes, files, and the Rust compiler yelling at me.
What is youdaheDB?
It’s a working key-value storage engine built on the same architecture that powers databases like RocksDB and LevelDB: the LSM-Tree (Log-Structured Merge Tree).
You can put keys, get keys, delete keys, and scan everything in sorted order — all through an interactive REPL. Kill the process mid-write, restart it, and your data is still there.
$ cargo run
Distributed DB Engine v0.2 (with SSTables)
db> put user:1 youdahe
OK
db> put user:2 alice
OK
db> get user:1
youdahe
Kill it. Restart it.
$ cargo run
[engine] Recovered 2 entries from WAL
db> get user:1
youdahe
Everything survived.
The Architecture
youdaheDB has four core components, each built from scratch:
1. Write-Ahead Log (WAL)
Before your database can do anything else reliably, it needs to be honest about what happened — even if the power goes out.
That’s what a Write-Ahead Log is. It’s a simple append-only log file on disk where every write gets recorded before it gets committed to the db in memory.
Think of it like a receipt printer: before your order is prepared, the kitchen gets the ticket. If something crashes, you replay the tickets from the beginning to reconstruct exactly where you left off.
Even though it hits disk first which is slower than memory, it doesn’t need to do any file seeks since it’s “append-only”. This is what makes it fast from a latency perspective because appending to the end of a file is an O(1) operation like adding to a Linked List.
When the db client sends a write, it can get a response back as soon as the new value is appended to the end of the log without needing to wait for it to be fully processed into the actual database. Evening updating the value for an existing key or deleting a key are operations that get appended to the end of the WAL.
You might be wondering how can a log be used to represent key value pairs? You’d expect something like a Hash Map not a Linked List. And how could adding another entry to the log change a value or delete anything?
The format of the log file is simple: length-prefixed key-value pairs in little-endian binary. The length shows where the entry begins and helps the log reader know where the current record ends so it can parse the next record.
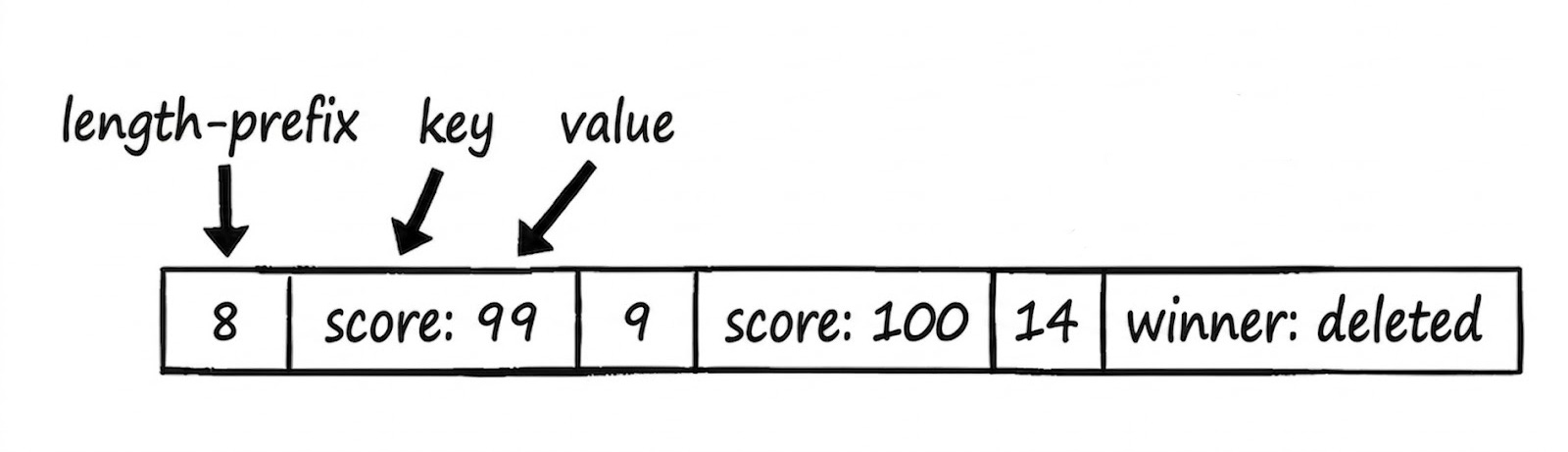
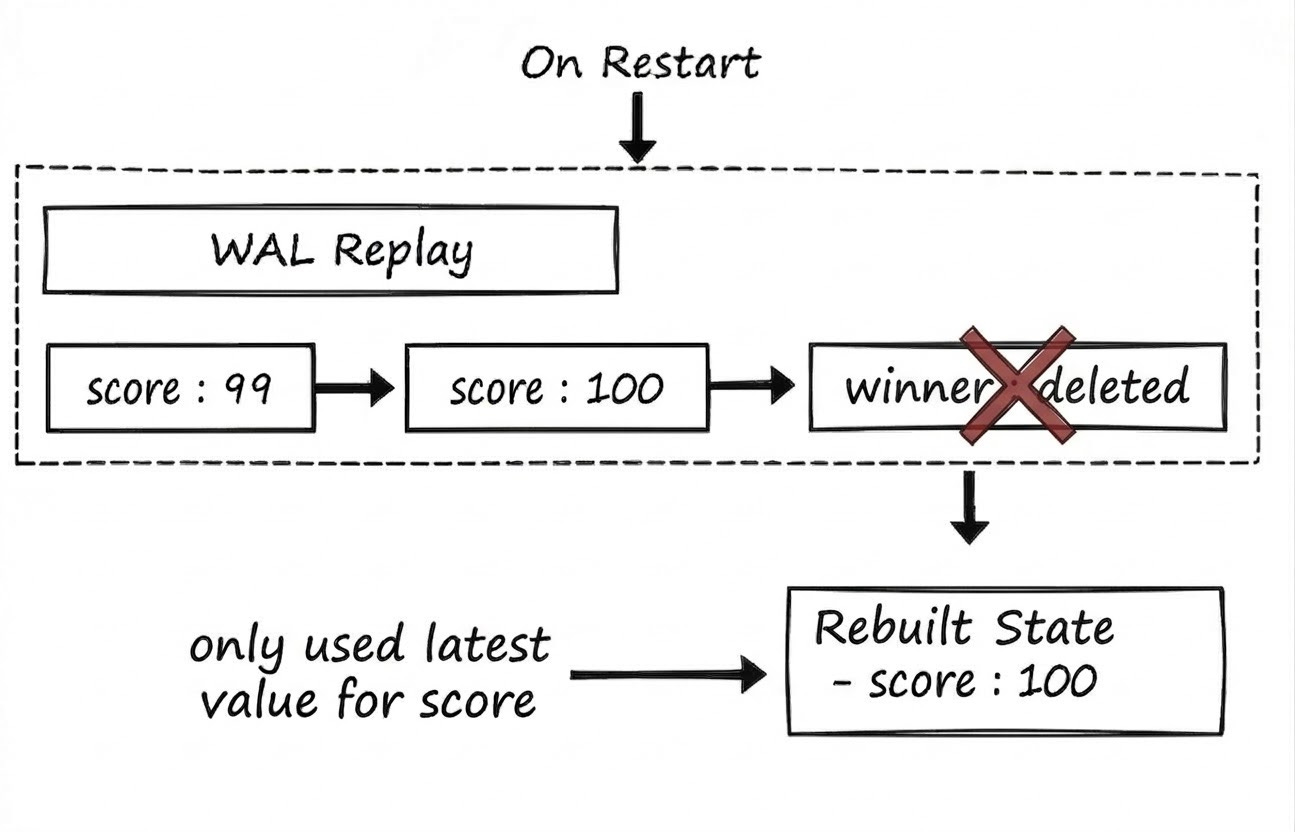
On restart, you replay the WAL from the beginning and rebuild your state in memory, which includes processing delete commands. If a key shows up twice, it just overwrites the value it saw before with the latest value.
2. MemTable
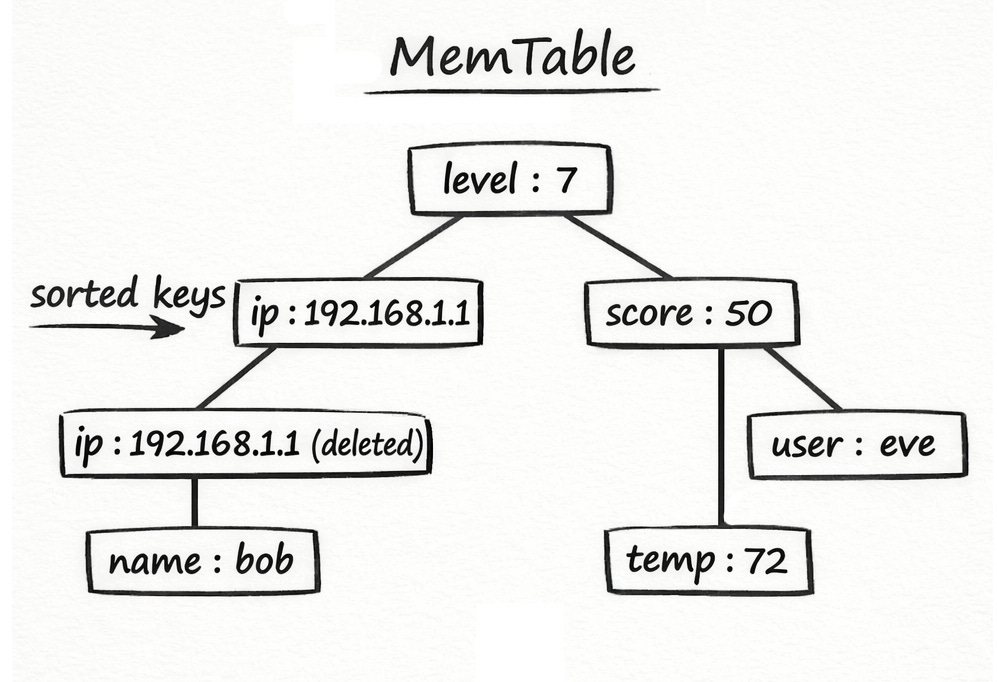
A MemTable (memory table) is the database’s active in-memory view of the latest data. After each write is appended to the WAL for durability, it’s also inserted into the MemTable so reads can see the newest value immediately without going to disk first.
In youdaheDB, the MemTable is backed by Rust’s BTreeMap, which keeps keys sorted automatically. That sorted order matters for two reasons: it makes range scans efficient (searching by a prefix of a key), and it makes flushing to disk simpler because the data is already in the right order for an SSTable (sorted on-disk file format described in the next section).
Updates overwrite older in-memory values for the same key, but deletes are still only marked for deletion rather than removing the key entirely, so older copies on disk do not come back later.
3. SSTables (Sorted String Tables)
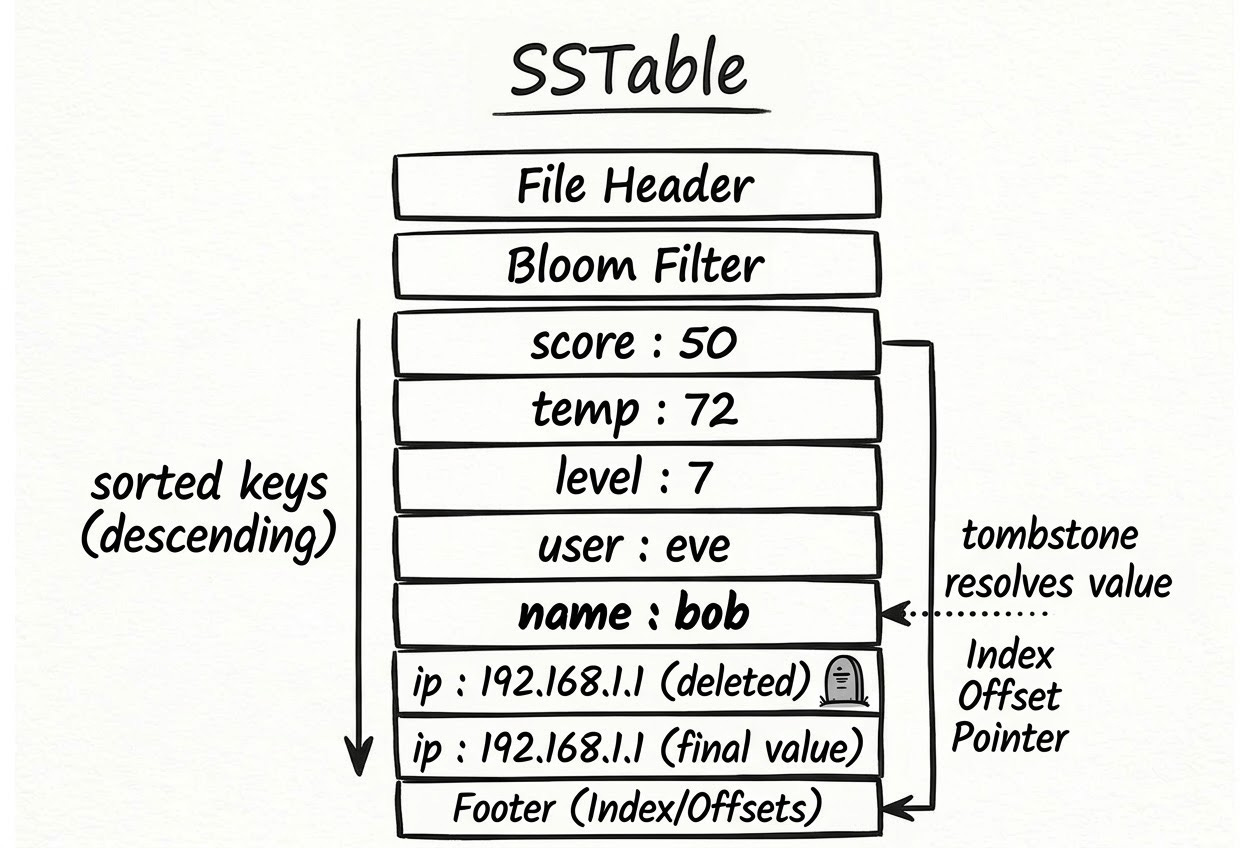
RAM is fast, but it’s limited in size. Once the MemTable grows past a certain threshold, youdaheDB flushes it to disk as an SSTable — a Sorted String Table and the MemTable is emptied.
An SSTable is an immutable, sorted file. “Sorted” means the keys are written in alphabetical order, which makes lookups efficient: once you scan past the key you’re looking for, you know it isn’t in this file. “Immutable” means once it’s written, it’s never modified — no partial updates, no corruption risk.
Over time, multiple SSTables accumulate on disk. Reads search them newest-to-oldest, and the first match wins.
4. Tombstones
When you delete a key, you can’t just erase it from the MemTable and call it a day. Older copies of that key may still exist in files on disk. If you silently removed the entry from memory, those older values would “reappear” the next time you went looking on disk.
The solution is a tombstone — a special marker that says “this key was deleted.” This is the missing piece to expalain how deletion is happening as described in the WAL, MemTable and SSTable.
Instead of removing the entry, youdaheDB inserts a None value for that key. When a read finds a tombstone, it knows to stop looking further and return “not found,” even if older copies exist on disk.
Tombstones are eventually cleaned up during compaction (more on that below).
5. The Storage Engine
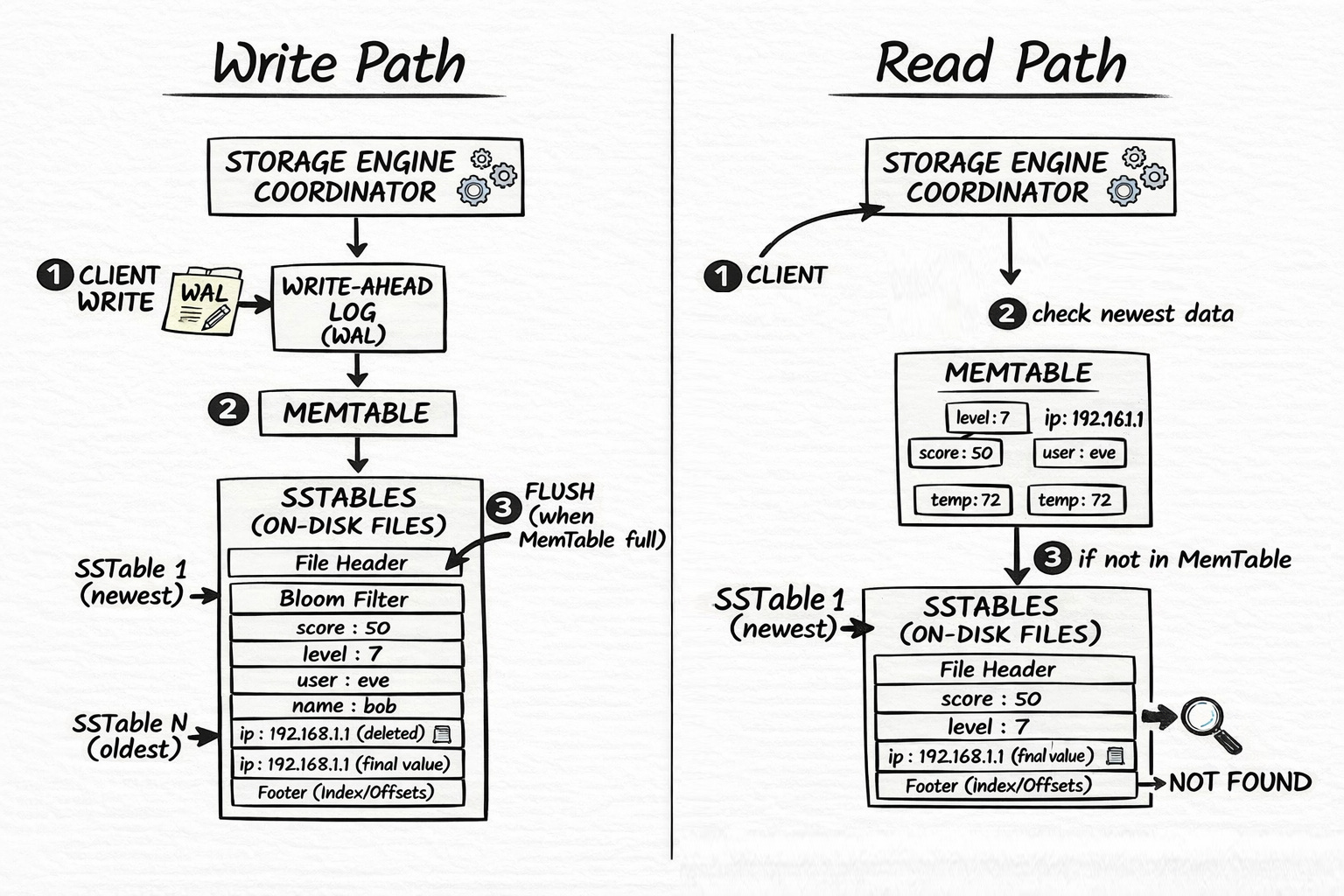
The coordinator that ties everything together. It owns the WAL, MemTable, and all SSTables.
Write path: WAL (durability) → MemTable (speed) → SSTable flush when full.
Read path: MemTable (newest) → SSTables newest-to-oldest → not found.
On startup, it discovers existing SSTable files on disk, replays the WAL to rebuild the MemTable, and you’re back in business.
The Roadmap
I’m building in public, youdaheDB is still early-stage. This article is part I in a series where I’ll explain from start to end how to build a production ready distributed database.
There’s a list of missing pieces waiting to be tackled:
Compaction is the big one. As SSTables accumulate, reads get expensive — the engine has to search more and more files. Compaction merges multiple SSTables into one: it sorts and combines all the entries, applies tombstones (permanently removing deleted keys), and discards superseded versions of the same key. Without compaction, the engine gets slower over time and wastes disk space on stale and deleted data.
Beyond compaction, what’s missing includes:
Bloom filters — probabilistic data structures that let the engine quickly rule out SSTables that definitely don’t contain a key, avoiding unnecessary disk reads
Indexes — structures that enable faster lookups without scanning files linearly
Checksums — to detect file corruption on disk
Manifests — a durable record of which SSTable files are current, so the engine doesn’t have to re-discover them on startup
WAL rotation — periodically replacing the WAL with a fresh file after old entries are safely flushed to SSTables
The Next Phase: Raft Consensus
A single-node database is useful, but what happens when that machine dies?
youdaheDB’s next phase is implementing the Raft consensus protocol to replicate data across multiple nodes. Consensus protocols exist to solve a hard problem: how do you get multiple machines to agree on the state of shared data, even when some of them crash or go offline?
The core idea in Raft: one node is elected leader, and all writes go through it. A write is only considered committed once a quorum — a majority of nodes — confirms they’ve stored it. If the leader dies, the remaining nodes hold an election and choose a new one. Because commit quorums and election quorums always overlap, any newly elected leader is guaranteed to have seen all previously committed data.
Each node maintains its own local persistent log that it uses to track and replay committed entries — similar in purpose to the single-node WAL. The Raft protocol coordinates these logs across the cluster: the leader sends log entries to followers, and once a majority acknowledges them, the entry is committed on all nodes. It’s not a single shared log — it’s a distributed agreement protocol that keeps independent local logs in sync.
Why Rust?
Rust’s ownership model is well-suited for database engineering. The borrow checker enforces memory safety at compile time — it eliminates whole classes of bugs like use-after-free and data races that are common in systems code written in C or C++.
That said, Rust doesn’t fully solve the reader-writer coordination problem on its own. For example: if one thread is serving reads while another is flushing the MemTable to an SSTable, Rust doesn’t automatically figure out how to coordinate that handoff. You still need to choose the right synchronization primitive — a Mutex, an RwLock, a channel — and reason carefully about the access pattern.
What Rust does do is make it much harder to accidentally create undefined behavior while doing that. In Java or Python, you might use locks incorrectly and not find out until a crash in production. In Rust, many of those mistakes won’t compile. It does not automatically prove that your concurrency design is correct though.
No garbage collector also means predictable latency. When you’re flushing a MemTable to disk or replaying a WAL, you don’t want a GC pause in the middle of it.
What I Took Away
Building a database from scratch teaches you things that no amount of SELECT * FROM ever will:
Why databases use WALs — sequential disk appends are fast; random writes are not
Why tombstones exist — you can’t just “delete” something when older copies live on disk
Why LSM-trees flush and compact — memory is fast but finite; disk is slow but abundant, and compaction keeps reads from getting too expensive over time
Why consensus is hard — getting 3 machines to agree on anything, while handling failures and network partitions, is a genuinely difficult problem
The entire thing is built with zero external dependencies. Just Rust’s standard library, a Cargo.toml, and a lot of binary serialization code.
youdaheDB isn’t production-ready. But it taught me more about how data actually lives and moves through a system than any tutorial ever could.
Check out the work in progress here on Github → youdaheDB
About The Author

Youdahe Asfaw is a Sophomore studying CS @ Gustavus Adolphus College, founder of an edtech platform called Docere, and an ML researcher. He specializes in infrastructure, building replicas of tools like Docker and Kubernetes from scratch.